Electric utilities are navigating a period of rapid change driven by electrification, renewable energy integration, climate variability, and evolving customer behavior. These trends are placing new demands on planning processes that have historically relied on empirical load data, such as advanced metering infrastructure (AMI) records or curated reference datasets. While these data sources remain valuable, they are constrained by privacy considerations, incomplete coverage, limited historical depth, and a limited ability to represent emerging technologies or future scenarios. Against this backdrop, synthetic customer load data has emerged as a complementary tool for utility planning and analysis.
Synthetic customer load data refers to artificially generated datasets designed to replicate the statistical, temporal, and spatial characteristics of real electricity consumption. Rather than representing actual customers, these datasets emulate patterns such as daily and seasonal demand, household diversity, and responses to technology adoption and weather conditions. When developed using appropriate safeguards, synthetic data can be shared and analyzed without exposing personally identifiable information, addressing one of the most persistent challenges associated with AMI data. The research examines two primary approaches to generating synthetic customer load data—simulation-based and generative AI-based—and evaluates their benefits, limitations, and potential roles in utility planning.
Motivation for Synthetic Load Data
Utilities face several structural limitations when relying solely on empirical AMI datasets. Privacy concerns often require restrictive data governance policies and, in some cases, explicit customer consent for data sharing, adding cost and complexity to collaboration with third parties. AMI deployment, while widespread, remains uneven, and even mature systems typically offer less than a decade of historical data. In addition, customers who opt in to data sharing may not be representative of the broader population, introducing potential biases into planning studies. Managing AMI data also imposes a significant computational and financial burden, as utilities must store, secure, curate, and process large volumes of high resolution time series data.
Synthetic data tools help address these challenges by reducing dependence on sensitive customer records and enabling scalable, flexible scenario analysis. Once developed and benchmarked, synthetic datasets can be generated quickly, labeled consistently, and adapted to evaluate future technology, policy, and climate scenarios that are not yet reflected in historical data. As a result, synthetic load data allows planners to focus more on analysis and decision making rather than data acquisition and management.
Utility and Customer Use Cases
The applications of synthetic customer load data extend beyond traditional forecasting and resource planning. Synthetic datasets can be used to augment sparse or anonymized AMI records, filling gaps in temporal, geographic, or behavioral detail. They support modeling of emerging technologies, such as electric vehicles, heat pumps, and distributed solar, enabling utilities to assess adoption pathways and design forward-looking programs. Synthetic data is also valuable for grid resilience and extreme event analysis, allowing planners to test system performance under severe weather or high load conditions.
On the customer side, synthetic data can underpin energy audits, diagnostics, and advanced analytics tools without relying on sensitive usage records. It can support personalized tariff comparisons and efficiency insights while preserving privacy. In addition, synthetic datasets facilitate collaboration among utilities, regulators, and researchers by providing a common, shareable resource, and they can be used in education and workforce development to build expertise in energy analytics and grid planning.
Case Study: Insights from the Faraday Model

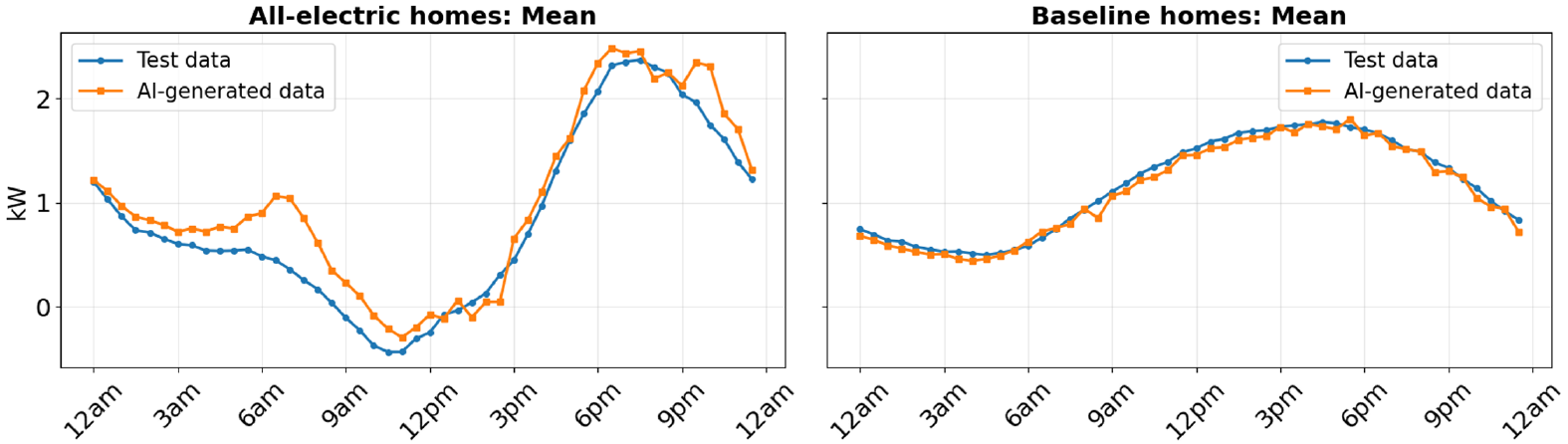
To explore the applicability of generative AI for generating synthetic customer load data, the paper presents a case study using the Faraday model developed by the Centre for Net Zero. Faraday employs a customized variational autoencoder architecture designed to capture the positively skewed distribution of residential electricity demand, including infrequent high load events. For this study, Faraday was trained on simulated U.S. residential load data generated with EPRI’s LoadSim tool, which provided a proxy for large volumes of labeled AMI data.
The study modeled 2,000 single-family homes in Knoxville, Tennessee, split evenly between all-electric and baseline fossil-fueled configurations. After training, the model generated thousands of synthetic daily load profiles in under a minute. Comparisons between synthetic and holdout test data showed that Faraday could reproduce key characteristics of residential demand, including differences across technology configurations, the impact of rooftop solar, and electric vehicle charging behavior. While overall fidelity was reasonable, the analysis also highlighted limitations related to extreme events, unobserved technology combinations, and the inability to capture multi day dynamics when profiles are generated independently.
Summary and Outlook
Synthetic customer load data offers utilities a flexible, privacy preserving complement to traditional AMI datasets. Simulation based and generative AI based approaches each provide distinct advantages and face distinct limitations. Simulation-based models offer transparency, physical grounding, and strong performance in long-term and climate-focused analyses, but they can be computationally intensive and require specialized expertise. Generative AI models provide speed, scalability, and the ability to capture complex behavioral patterns. Still, they depend on high quality training data and face challenges in modeling extremes and unobserved scenarios.
The intended application should guide the choice between approaches, and hybrid methods combining physics based simulations with generative AI may offer a promising path forward. By strengthening benchmarking efforts, establishing common standards, and piloting real world implementations, utilities can build confidence in synthetic datasets. Over time, these tools can support more informed decision making, enhance collaboration, and help the energy sector prepare for an increasingly complex and uncertain future.
Microsoft Copilot was used to generate a draft of this article from an EPRI publication. AI-generated content was reviewed, edited, and fact-checked by an EPRI expert to ensure accuracy and quality.
Learn More
- EPRI White Paper: Synthetic Customer Load Data – Approaches, Limitations, and the Role of Generative AI

